Agent Loops: 15 AI Agent Business Ideas Ranked by Demand
For the past few weeks, the loudest conversation in the builder corner of X has been Claude loops: agent loops that plan, build, and judge on a cycle instead of answering a single prompt. Dozens of writers have covered the pattern, and the four largest posts alone reached 13.6 million impressions, with the biggest field guide collecting 23,519 bookmarks. When a workflow gets bookmarked at four times the rate it gets liked, something is cooking. This report asks the unglamorous follow-up question the trend itself never asked: which of these AI agent ideas would actually survive demand validation?
The short answer: one of the 15 rates PROMISING. Contract Redline Loop scored 64.7 out of 100, the third-highest score across all 733 ideas the engine has ever run. The rest of this report shows how the 15 were engineered and what the scores reveal.
Key Takeaways
The wave: 13.6 million impressions in two weeks
Credit belongs up front. Anatoli Kopadze wrote the definitive loops field guide: 12.27 million impressions and 23,519 bookmarks, a reference asset rather than a viral take. MIKE mapped the failure modes (the missing memory file, the unsplit sub-agents, the stop conditions) and reached 1.28 million people from a 13K-follower account. Rahul gave the pattern a pocket-sized name: Plan, Build, Judge, Repeat. And Delba compressed the paradigm into three lines about writing the loop that runs the prompt that writes the code.
These four posts taught millions of builders HOW loops work. This analysis stands on that work and adds the layer those posts were never trying to provide: WHERE the demand is.
A trend is not a business
Trend posts discuss patterns. Patterns are not business ideas, and telling the two apart from a timeline is close to impossible: momentum measures attention while demand measures money, and the two correlate less than the feed suggests. Fluenta calls this distance the Trend-to-Demand Gap, and it is the same gap documented in the Top-50 June report, where boring, budget-attached ideas beat flashy trending ones on demand data.
So instead of guessing which loop patterns might work, the analysis went the other way around.
How the 15 ideas were engineered
Between March and May 2026, the Fluenta engine scored 718 business ideas from launch platforms, accelerators, VC lists, research reports, and social feeds. Each idea receives a Launch Readiness Score (LRS): a 100-point, demand-weighted score built from a stack of signals, with search demand and pain carrying the heaviest weights, alongside entry difficulty, funding momentum, urgency, budget proof, and monetization. One rule applies to every number below: an LRS is a demand prediction, not a verdict. The highest score ever recorded is 66.2 out of 100, and no idea has ever rated HOT. The instrument is deliberately hard to impress.
The top decile of those 718 ideas (cutoff 55.5) shares a measurable fingerprint. Budget proof separates hardest: top-decile ideas score 1.79x the population average on evidence that buyers already pay for a solution today. Raw search demand lifts 1.25x. And counterintuitively, the winners sit in MORE crowded markets. The competition signal rewards empty markets, and top-decile ideas score 36% below average on it. Empty markets are usually empty for a reason. Ease of entry predicts nothing (1.02x).
The 15 loop ideas below were reverse-engineered from that fingerprint: each takes a loop pattern from the viral posts and rebuilds it as a business attached to an existing budget line, in a market where named incumbents already prove buyers pay.
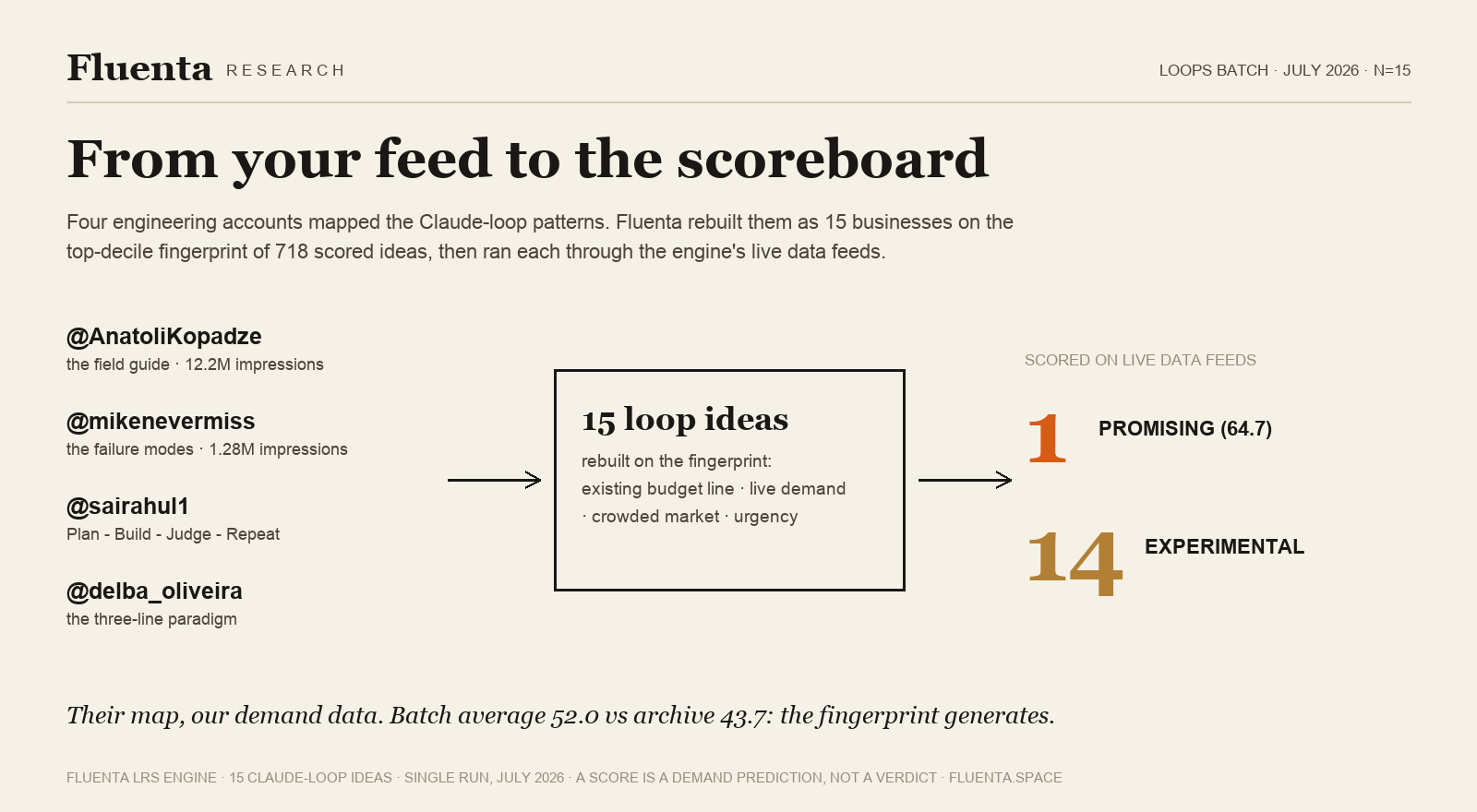
Because the batch was engineered to score high, celebrating high scores would be circular. The honest test: can the recipe run in reverse and produce good ideas on purpose? It can. The 15 loops averaged 52.0 LRS against the archive's 43.7 baseline, a statistical tie with the strongest set ever run through the engine (a Product Hunt-sourced batch at 51.7). The chance that a random 15 ideas from the archive average 52.0 or better is under 1%. The scoring rubric works as a generation recipe.
The 15 loop ideas, ranked
One idea rates PROMISING: Contract Redline Loop at 64.7, the third-highest score across all 733 ideas ever run (one scoring run, so call it top 1% rather than a precise rank). Fourteen rate EXPERIMENTAL, with a batch median of 51.6. Four ideas clear the floor of the published Top-50 (56.8). The full interactive table with every signal score sits at the bottom of this page, and each row credits the writer whose post seeded the pattern.
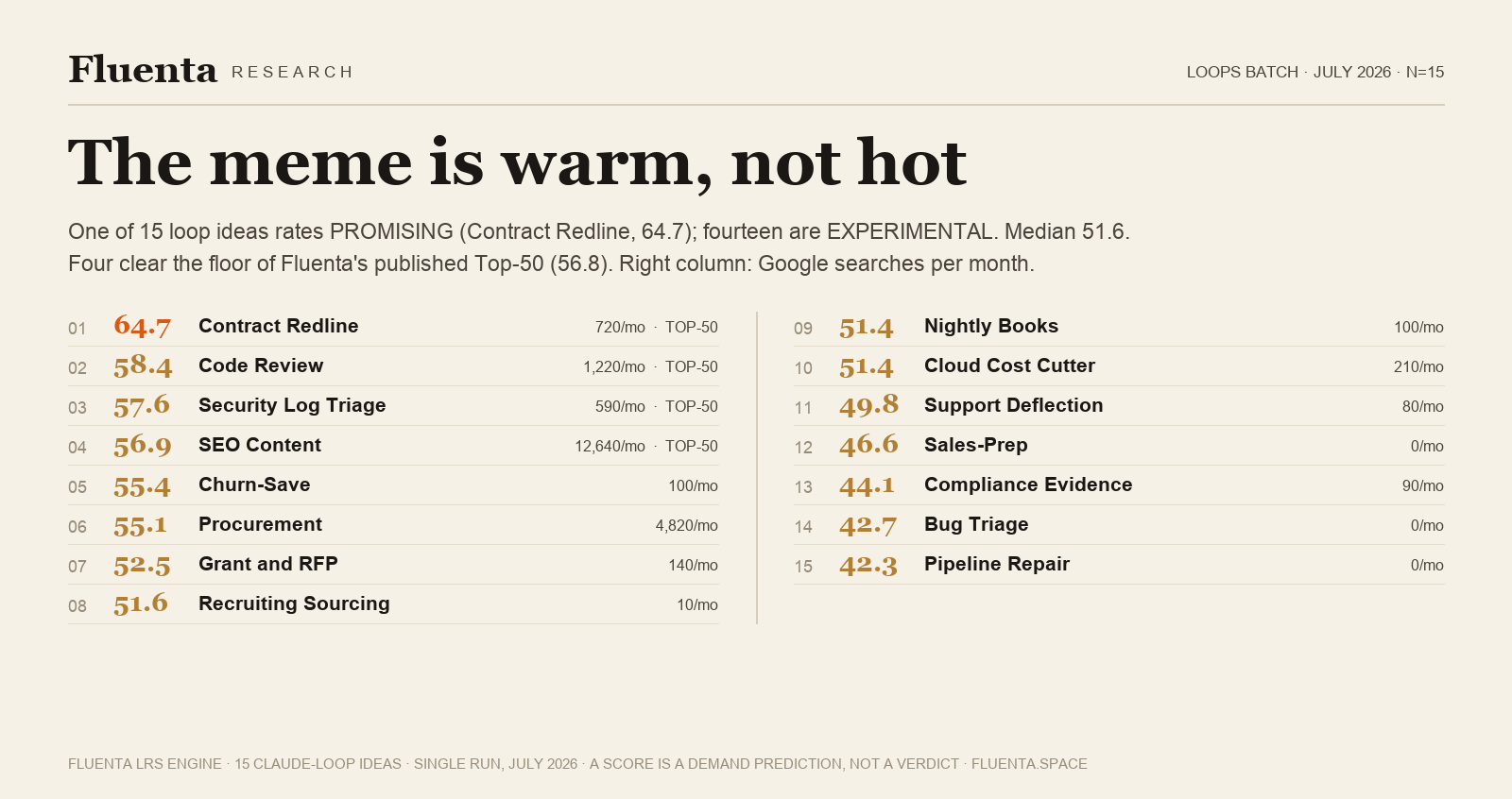
Sector does not save an idea: the legal and compliance cluster contains both the crown (64.7) and one of the weakest rows (44.1). The specific workflow, not the sector, does the work.
Five findings the viral posts never tested
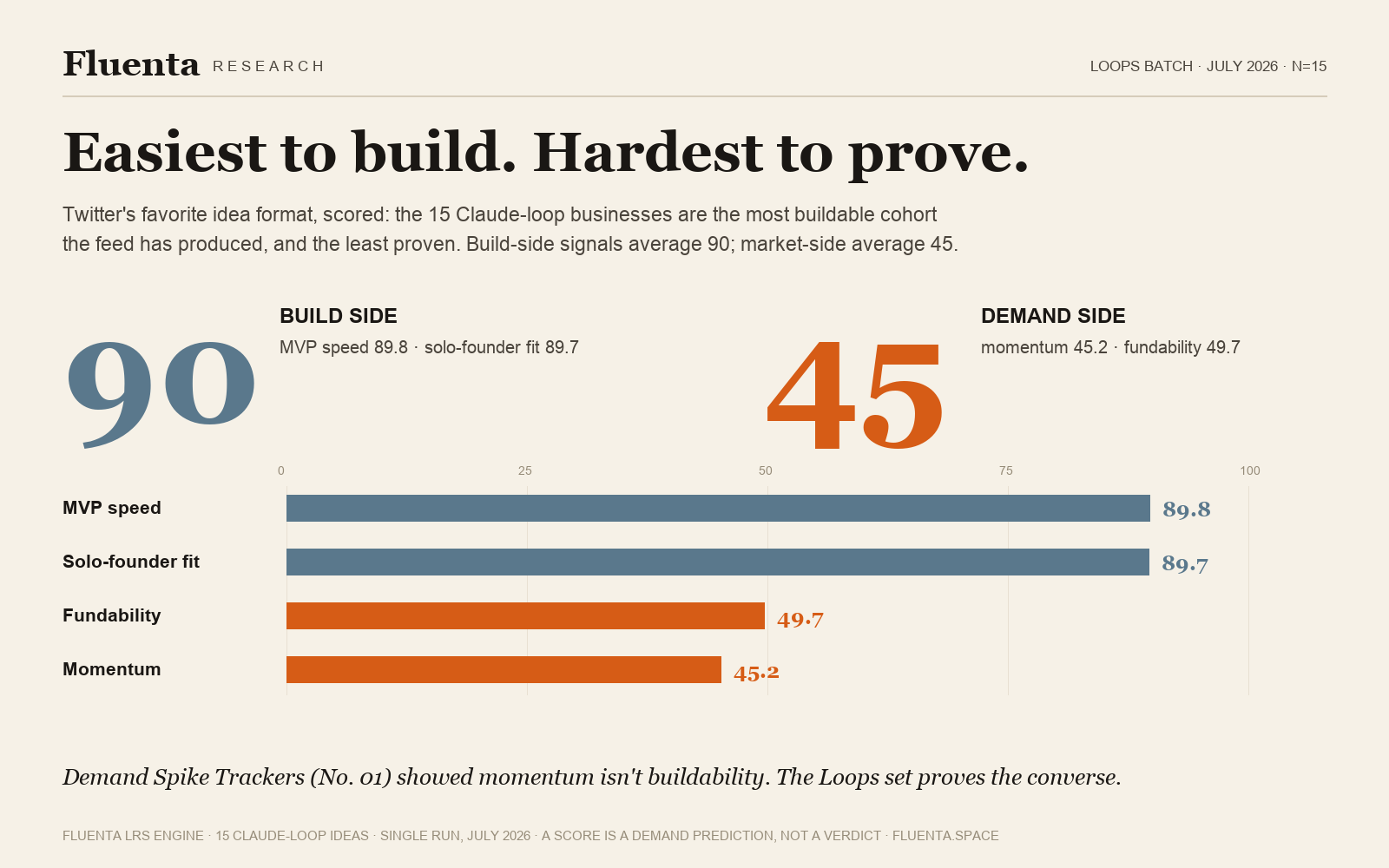
Easiest to build, hardest to prove
The 15 loops are the most buildable cohort the engine has produced: MVP-speed averages 89.8 out of 100 and solo-founder fit 89.7. Their market-side signals average 45.2 (momentum) and 49.7 (fundability). Ninety versus forty-five. The ideas easiest to ship this weekend are precisely the ones with the least proven pull, which is the mirror image of the finding in the trend-tracker analysis: momentum without buildability there, buildability without momentum here.
The search desert
Ten of the 15 loops get 210 or fewer Google searches a month. Three get exactly zero (Sales-Prep, Bug Triage, Pipeline Repair). Pain is chronic on every loop, scoring 17 to 25 out of 30 across the board, but the category names are so new that nobody searches for them yet.
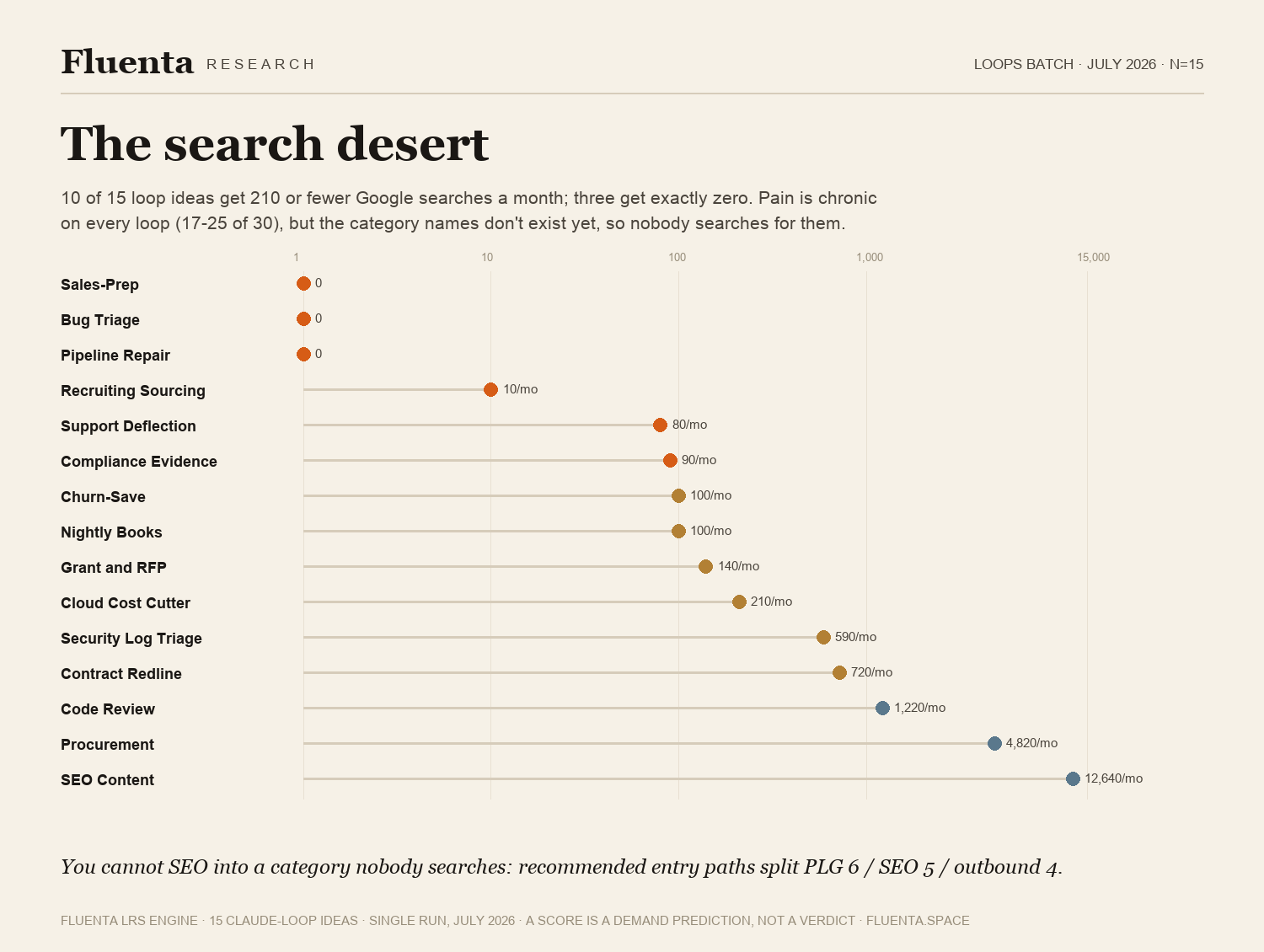
The practical consequence: a category nobody searches cannot be entered through SEO. The engine's recommended entry paths for the batch split accordingly: product-led growth for 6 ideas, SEO-led for 5, outbound-first for 4.
One honesty note on the three zeros: the demand signal reads Google, and developer demand does not live on Google. It lives in GitHub, Stack Overflow, and marketplace listings. Bug Triage's own evidence file cites Sentry and Datadog serving Fortune 500 clients; on its non-demand signals it would rank fourth in the batch. The coding loops (the very patterns the four writers demoed) read as crowded, incumbent-owned, and invisible to search data, not as unwanted.
The 59x toll road
Identical loop mechanic, wildly different cost of attention. Median cost-per-click across the 15 ideas runs from $2.96 (Nightly Books) to $173.64 (Contract Redline), a 59x spread. The technology is commodity; where it gets pointed sets the toll.
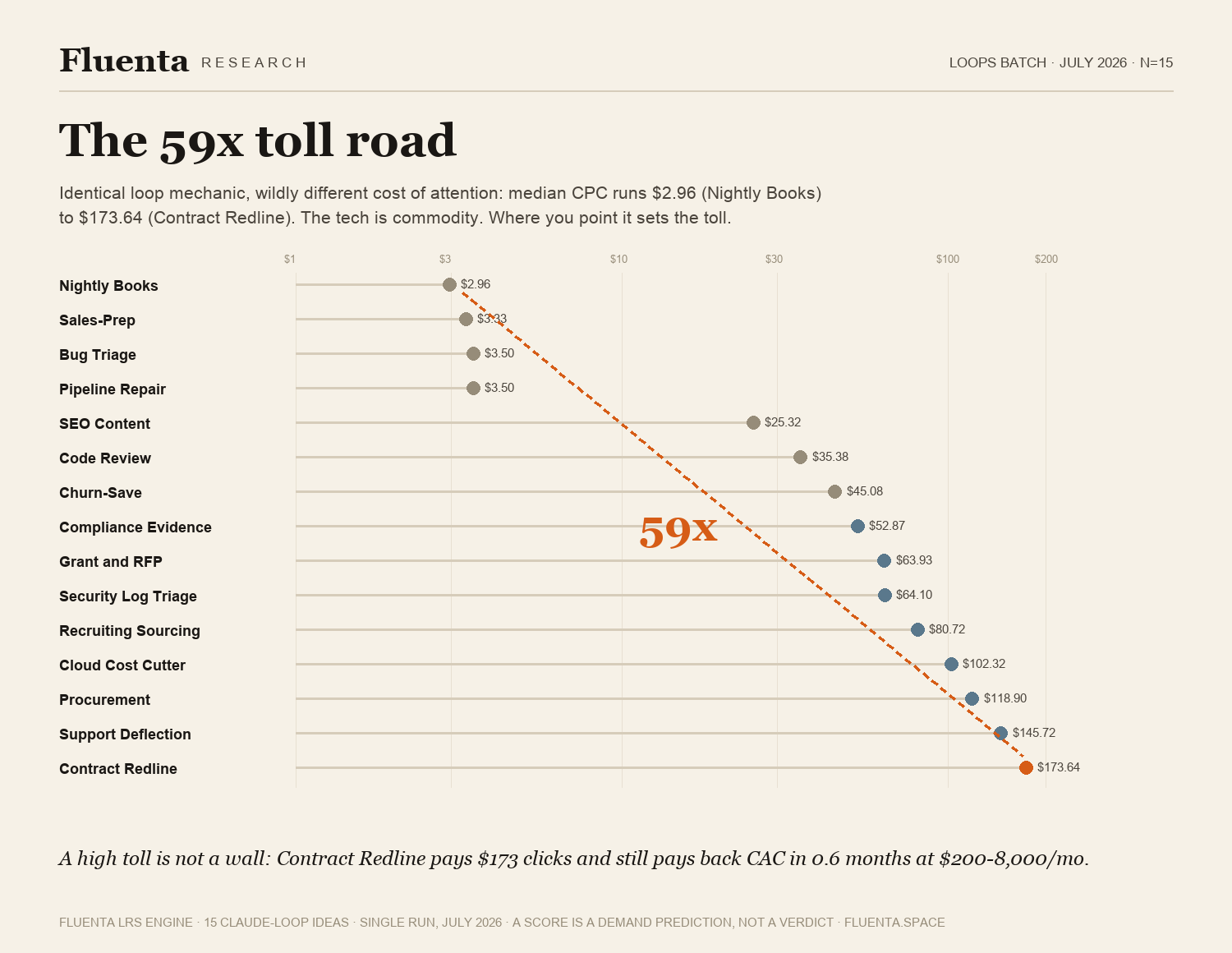
A high toll is not a wall. Contract Redline pays the batch's most expensive clicks and still recovers customer acquisition cost in 0.6 months, because its price ceiling absorbs it.
Pricing beats tech
The batch's #2 idea has its worst viable unit economics. Code Review Loop scores 58.4, top 6% of everything ever run, and its estimated CAC payback is 61.8 months: developers expect $1 to $50 a month while acquisition costs run $354 to $1,179. Contract Redline, four points higher on demand, charges $200 to $8,000 a month and pays back in 0.6 months. Same automation, 100x the price ceiling.

The one-line version: charge like a lawyer, not like a dev tool.
The legal crown
Contract Redline Loop is the only idea in the batch with perfect scores on funding momentum, budget proof, and monetization. All five of its funding comps closed in 2026. Lexroom's $50M Series B landed six weeks before this run. Incumbents like Ironclad already serve Visa and Salesforce, which under the fingerprint is a feature, not a bug: competition is evidence the money is real. Lawyers are the ideal loop customer: expensive time, repetitive documents, existing budget. The same scoring run works on any idea.
Agent loops vs. agentic workflows
Two terms travel together in this conversation and mean different things. An agentic workflow is any multi-step process an AI agent executes: research, drafting, orchestration, handoffs. An agent loop (also called an agentic loop) is the self-correcting subset: the agent plans, builds, judges its own output, and repeats until a stop condition is met, which is what lets it run unattended overnight. The distinction matters commercially. Agentic workflows are the broad category incumbents and investors already fund; agent loops are the wedge, because the judge step is what turns a demo into a service a business can leave running against a real budget line. Every idea in the table above is a loop in that strict sense: continuous, self-checking, human-approved at the edge.
How to read these scores
Three caveats.
First, a high LRS does not guarantee a successful business. It predicts that demand exists. The best idea of 733 scored 66.2 out of 100; the engine has never met a sure thing.
Second, an idea is not an execution. Every row in the table can be executed dozens of meaningfully different ways: different wedge, different buyer, different pricing, different depth of loop autonomy. Some executions of a 64.7 idea will fail; some executions of a 44.1 idea will win. The score prices the demand; the builder supplies the execution.
Third, this list is a starting set, not a canon. Other loop ideas are welcome and possibly better; these 15 are simply the ones the fingerprint method produced from the four viral posts.
Methodology disclosure: this run scored without X-native signals (the engine's X feed was disabled during the batch), so the scores rest on search, funding, pricing, and buyer-evidence data. Competitor-count and social-mention fields are capped metrics and were excluded from every finding above.
Do the same with your trend
The method in this report is repeatable by anyone, on any trend. Watch the trend that interests you. Generate a handful of business ideas around it, biased toward existing budget lines and markets where incumbents prove buyers pay. Then score each one with Fluenta X-Ray and compare: of five ideas that all sound plausible on a timeline, demand data usually separates one or two worth building from the rest. That is the entire point of the instrument: fewer bets on vibes, more bets on demand.
All of this also runs without leaving the editor: the Fluenta MCP plugs the engine into Claude or Cursor, so a batch of trend ideas can be generated, scored, and stress-tested in the same chat window, the way this report's batch was. Each result arrives as a rich idea card, downloadable as markdown or text with the metrics, named competitors, and business model paths inside. The card below is the live one for this report's top scorer: open it, flip it, and take the full data with you. A step-by-step walkthrough lives in the Cursor X-Ray tutorial.

Contract Redline Loop
Source: X - Boris Cherny (@sairahul1)The loops wave will produce real companies. The scores say where to dig.
“You're not supposed to prompt Claude. You're supposed to build a system that prompts itself.”
All 15 agent-loop ideas, scored
Every idea traces to one of the four viral posts (credit column links the source). Scores are from a single engine run on July 2, 2026. An LRS is a demand prediction, not a verdict.
Contract Redline Loop64.7›
What it does. Redlines every inbound contract against the company playbook before a lawyer opens it.
Sector. Legal, Compliance & Govtech
Pattern credit. @sairahul1
Google searches per month. 720/mo
LRS breakdown
Code Review Loop58.4›
What it does. Reviews every pull request against team standards, flags bugs and drafts fixes before a human merges.
Sector. Developer Tools & Infrastructure
Pattern credit. @delba_oliveira
Google searches per month. 1,220/mo
LRS breakdown
Security Log Triage Loop57.6›
What it does. Reads security logs and alerts overnight, clusters the noise and escalates real incidents with a summary.
Sector. Cybersecurity & Identity
Pattern credit. @mikenevermiss
Google searches per month. 590/mo
LRS breakdown
SEO Content Loop56.9›
What it does. Audits a site continuously, drafts on-page fixes and fresh content, and re-prioritizes against ranking moves.
Sector. Marketing & Sales Tech
Pattern credit. @AnatoliKopadze
Google searches per month. 12,640/mo
LRS breakdown
Churn-Save Loop55.4›
What it does. Watches usage and billing signals, flags at-risk accounts and drafts tailored save-plays for the CSM.
Sector. Marketing & Sales Tech
Pattern credit. @AnatoliKopadze
Google searches per month. 100/mo
LRS breakdown
Procurement Loop55.1›
What it does. Gathers vendor quotes, scores them against requirements and drafts purchase orders on a recurring cycle.
Sector. Boring Businesses
Pattern credit. @AnatoliKopadze
Google searches per month. 4,820/mo
LRS breakdown
Grant and RFP Loop52.5›
What it does. Scans for relevant grants and RFPs and drafts first-pass applications matched to the company profile.
Sector. Legal, Compliance & Govtech
Pattern credit. @sairahul1
Google searches per month. 140/mo
LRS breakdown
Recruiting Sourcing Loop51.6›
What it does. Continuously sources and screens candidates for a role and drafts personalized outreach.
Sector. HR, Hiring & Talent
Pattern credit. @sairahul1
Google searches per month. 10/mo
LRS breakdown
Nightly Books Loop51.4›
What it does. Reconciles transactions and drafts the monthly close every night; a human approves each morning.
Sector. Accounting, Tax & Finance Ops
Pattern credit. @AnatoliKopadze
Google searches per month. 100/mo
LRS breakdown
Cloud Cost Cutter Loop51.4›
What it does. Monitors cloud and SaaS bills nightly, flags waste and anomalies, and drafts rightsizing changes for approval.
Sector. Cloud & SaaS Infrastructure
Pattern credit. @mikenevermiss
Google searches per month. 210/mo
LRS breakdown
Support Deflection Loop49.8›
What it does. Owns the support queue overnight, resolves repetitive tickets and escalates the rest with full context.
Sector. Customer Support & CX
Pattern credit. @mikenevermiss
Google searches per month. 80/mo
LRS breakdown
Sales-Prep Loop46.6›
What it does. Before every meeting on the calendar, researches the account and drafts a one-page brief with three questions.
Sector. Marketing & Sales Tech
Pattern credit. @sairahul1
Google searches per month. 0/mo
LRS breakdown
Compliance Evidence Loop44.1›
What it does. Continuously collects SOC2/ISO audit evidence and flags gaps before the auditor does.
Sector. Legal, Compliance & Govtech
Pattern credit. @AnatoliKopadze
Google searches per month. 90/mo
LRS breakdown
Bug Triage Loop42.7›
What it does. Watches production errors, reproduces and clusters them, and drafts the fix as a pull request.
Sector. Developer Tools & Infrastructure
Pattern credit. @delba_oliveira
Google searches per month. 0/mo
LRS breakdown
Pipeline Repair Loop42.3›
What it does. Watches ETL jobs, diagnoses breakages and ships the fix once a human approves.
Sector. Data & Analytics
Pattern credit. @mikenevermiss
Google searches per month. 0/mo
LRS breakdown
X-native signals were not collected on this run (engine X feed disabled); scores rest on search, funding, pricing, and buyer-evidence data. Competitor-count and social-mention fields are capped metrics, excluded from all findings.
The top idea in this report scored 64.7 of 100. Where does yours land? An X-Ray runs one idea through the same live data feeds, scores it against all 733 ideas in this dataset, and returns the same card as above: downloadable, with named competitors, pricing anchors, and entry paths. 20 minutes, from $7, in the web app or through the Fluenta MCP inside Claude or Cursor.
Fluenta X-Ray, the instrument behind every score in this report
FAQ
What is an agent loop?+
An agent loop is an AI agent pattern that cycles plan, build, judge, repeat instead of answering a single prompt: the agent checks its own output against a goal and keeps iterating until a stop condition is met, which lets it run unattended. The pattern was popularized in June 2026 by Claude Code engineering posts on X that reached 13.6 million impressions. This report scores 15 business ideas built on that pattern.
What is the Launch Readiness Score (LRS)?+
A 100-point, demand-weighted score for business ideas. Search demand and pain carry the heaviest signal weights, alongside entry difficulty, funding momentum, urgency, budget proof, and monetization. The highest score ever recorded across 733 ideas is 66.2, and no idea has ever rated HOT. An LRS is a demand prediction, not a verdict.
Does a high LRS guarantee a successful business?+
No. The score predicts that demand exists; it says nothing about execution. Every idea can be executed dozens of different ways, and some executions of a high-scoring idea will fail while some executions of a mid-scoring idea will win.
Why do the coding loops score so low when they are the most viral?+
The demand signal reads Google search, and developer demand lives in GitHub, Stack Overflow, and marketplaces instead. Bug Triage and Pipeline Repair read zero monthly searches while their own evidence files cite incumbents like Sentry and Datadog serving Fortune 500 clients. The honest read is crowded and invisible to search data, not unwanted.
How are agent loops different from agentic workflows?+
An agentic workflow is any multi-step process an AI agent executes. An agent loop is the self-correcting subset: the agent plans, builds, judges its own output, and repeats until a stop condition is met, letting it run unattended. Commercially, workflows are the broad funded category; loops are the wedge, because the judge step turns a demo into a service that runs against a real budget line.
Can this method be repeated on a different trend?+
Yes. Pick a trend, generate ideas around it biased toward existing budget lines and markets with paying incumbents, then score each idea with Fluenta and compare. Demand data usually separates one or two ideas worth building from the rest.
Cite this article
Researchers and journalists: this article is freely citable. Click to copy the academic-format reference for your bibliography or footnote.
Ivanov, O. (2026). Agent Loops: 15 AI Agent Business Ideas Ranked by Demand. Fluenta. Retrieved from https://fluenta.space/resources/reports/agent-loops.
About the author

Oleg Ivanov
Co-founder & CEO, Fluenta
Oleg is co-founder and CEO of Fluenta. He spent the last decade shipping products across fintech, commerce, and AI tooling, and now leads Fluenta's work scoring startup ideas against 25 live market and social data feeds.
Related Resources
Validation
How to Validate a SaaS Idea in 2026 (Without Asking Your Friends)
Most validation advice is therapy. This is the only sprint that kills your idea with money — a 6-stage, 72-hour framework for solo & small-team founders, built on commitment signals from strangers. CB Insights-grade data, CEO-authored.
Founder Playbook
Customer Discovery Playbook: 12 Interview Scripts (2026)
12 customer discovery scripts tested across 47 founder interviews. Copy-paste ready. The exact questions that surface real demand vs polite lies.
Report
YC Spring 2026 Batch: All 194 Companies, Scored
We scored every company in YC's Spring 2026 batch on six public signals before Demo Day. The findings, the four groups, and a searchable board of all 194 with the questions each founder will get asked.
Score your idea in 20 minutes
Run Fluenta X-Ray on your idea. 25 live market + social feeds. Real demand data, real competition, real willingness-to-pay signals. From $7. 20 minutes.
Was this helpful?